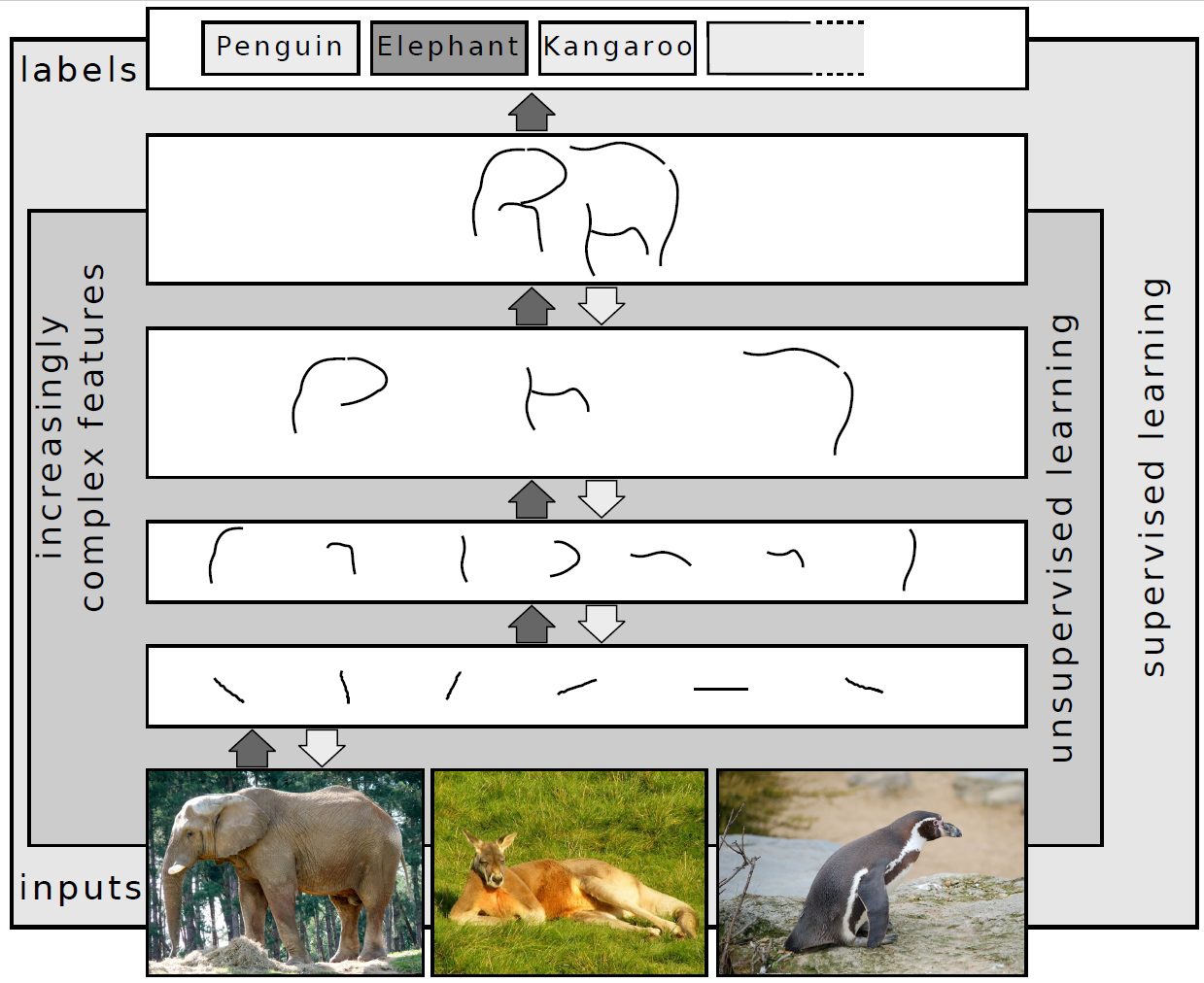
Miért konvolúciós hálózat képekhez?
Egy 224×224 pixeles RGB kép 150 528 bementi értéket tartalmaz. Ha ezt teljesen összekapcsolt (fully connected) réteggel dolgoznánk fel, minden neuronhoz annyi súly kapcsolódna, ahány bemeneti érték van — ez memóriában és számítási kapacitásban kezelhetetlen lenne nagyobb hálózatoknál.
A konvolúciós rétegek ezt az összekapcsoltságot szűrőkkel (kernelekkel) oldják meg: egy kis méretű szűrő — tipikusan 3×3 vagy 5×5 — végigcsúszik a képen, és minden pozícióban ugyanazokat a súlyokat alkalmazza. Ez súlymegosztás (weight sharing), ami dramatikusan csökkenti a paraméterek számát, miközben megőrzi a térbeli összefüggéseket.
A konvolúciós réteg
A konvolúciós réteg bemenete egy kétdimenziós (vagy háromdimenziós csatornák esetén) jellemzőtérkép. A szűrő pontszorzatot végez saját maga és a kép egymást átfedő részletei között, majd aktivációs függvényen (jellemzően ReLU-n) keresztül új jellemzőtérképet hoz létre.
Fontos paraméterek:
- Kernel mérete: A szűrő dimenziói (pl. 3×3). Kisebb kernel finom részleteket detektál, nagyobb kernelnél tágabb kontextus érzékelhető.
- Lépéshossz (stride): Azt határozza meg, hogy a szűrő mekkora lépésközzel halad végig a bemeneten. Nagyobb stride kisebb kimeneti jellemzőtérképet eredményez.
- Párnázás (padding): A bemeneti kép széleihez hozzáadott nulla értékű sorok és oszlopok, amelyek szabályozzák a kimeneti méretet és megőrzik a szélső pixelek hatását.
- Csatornák száma (filters): Egy konvolúciós réteg több szűrőt tartalmaz párhuzamosan, mindegyik különböző jellemzőt detektál.
Pooling rétegek
A pooling rétegek feladata a jellemzőtérképek térbeli felbontásának csökkentése, ezáltal a hálózat invariánsabbá válik kis eltolásokra és torzításokra. A leggyakoribb típus a max pooling, amely egy meghatározott régióból a maximális értéket tartja meg.
Az average pooling az átlagot veszi, ami egyes architektúrákban — különösen a globális average pooling alkalmazásánál a hálózat végén — előnyösebb. A pooling rétegek nem tartalmaznak tanulható paramétereket.
Kiemelkedő architektúrák
LeNet-5 (1998)
Yann LeCun és munkatársai által fejlesztett hálózat, amelyet kézírt számjegyek felismerésére terveztek az MNIST adathalmazon. Az architektúra két konvolúciós-pooling réteget és három teljesen összekapcsolt réteget tartalmazott. Ez az első szisztematikusan betanított CNN, amelynek sikerét a valós alkalmazás is igazolta: az 1990-es évek végén az amerikai bankrendszerben csekk-feldolgozásra alkalmazták.
AlexNet (2012)
Az ImageNet Large Scale Visual Recognition Challenge 2012-es győztese, amelyet Krizhevsky, Sutskever és Hinton fejlesztett. Az AlexNet 8 réteget tartalmazott, GPU-n futott, ReLU aktivációt és dropout regularizációt alkalmazott. A versenyeredmény — a második helyezettnél közel 11 százalékponttal jobb top-5 hibaarány — megnyitotta a mélytanulás jelenlegi korszakát a számítógépes látásban.
VGGNet (2014)
Az Oxford Visual Geometry Group hálózata egy egyszerű elvvel dolgozik: kizárólag 3×3-as konvolúciós szűrőket alkalmaz, de mélyen egymás után halmozva. A VGG-16 és VGG-19 változatok 16 illetve 19 rétegből állnak. Előnyük az egyszerű, szabályos felépítés, hátrányuk a nagy paraméterszám (kb. 138 millió a VGG-16-ban).
ResNet (2015)
A Microsoft Research He és munkatársai által kifejlesztett maradék hálózat (residual network) bevezette az úgynevezett skip connection mechanizmust, amely lehetővé teszi, hogy a gradiens közvetlenül átáramoljon több rétegen keresztül. Ez megoldotta a nagyon mély hálózatok taníthatóságának problémáját, és lehetővé tette 50, 101 vagy akár 152 rétegű hálózatok sikeres betanítását.
Referencia: A ResNet eredeti leírása: He, K., Zhang, X., Ren, S., Sun, J. (2016). „Deep Residual Learning for Image Recognition". IEEE CVPR. A cikk az ImageNet versenyen 3.57%-os top-5 hibaarányt ért el, ami az első emberi teljesítmény alatti eredmény volt ezen a feladaton.
Alkalmazási területek
A CNN architektúrák nem korlátozódnak képfelismerésre. Más területeken is megjelennek:
- Orvosi képelemzés: Mellkasröntgenek elemzése, retinafotók értékelése, MRI szegmentáció.
- Autonóm járművek: Sávjelzők, közlekedési táblák és gyalogosok azonosítása.
- Ipari minőség-ellenőrzés: Gyártósori termékek vizuális hibáinak automatikus detektálása.
- Természetes nyelvfeldolgozás: Egydimenziós konvolúciókkal szöveg osztályozása.